
HDInsight allows users to run data transformation and interactive queries on different types of data. Interactive Hive (Hive on LLAP) is still in preview and as a result not available in Europe, old good Hive has to be tweaked to satisfy interactive queries.
In HDInsight data is stored separately and there can be many HDInsight clusters on the same storage accounts. One use case is to have a separate cluster for Data Scientists (interactive queries, data exploration) and another one for ETL jobs. The clusters can run independently, but preferably on different time slots (Blob Storage throughput limitations).
USE CASES
Interactive
- Common patterns: short running jobs over refined data
- Main problems: how to use BI tools, how to utilize produced datasets
- Optimization: as in ETL + use different setup than ETL cluster (see below)
ETL
- Common patterns: fire and forget, long running jobs, full table scans
- Main problems: how to schedule, make operationale, cost based optimizations
- Optimization: tweak joins, mappers, reducers, memory settings, etc. all you can find
CLUSTER SETTINGS
(You can change those settings in Ambari UI/Hive/Configuration or change corresponding configuration files)
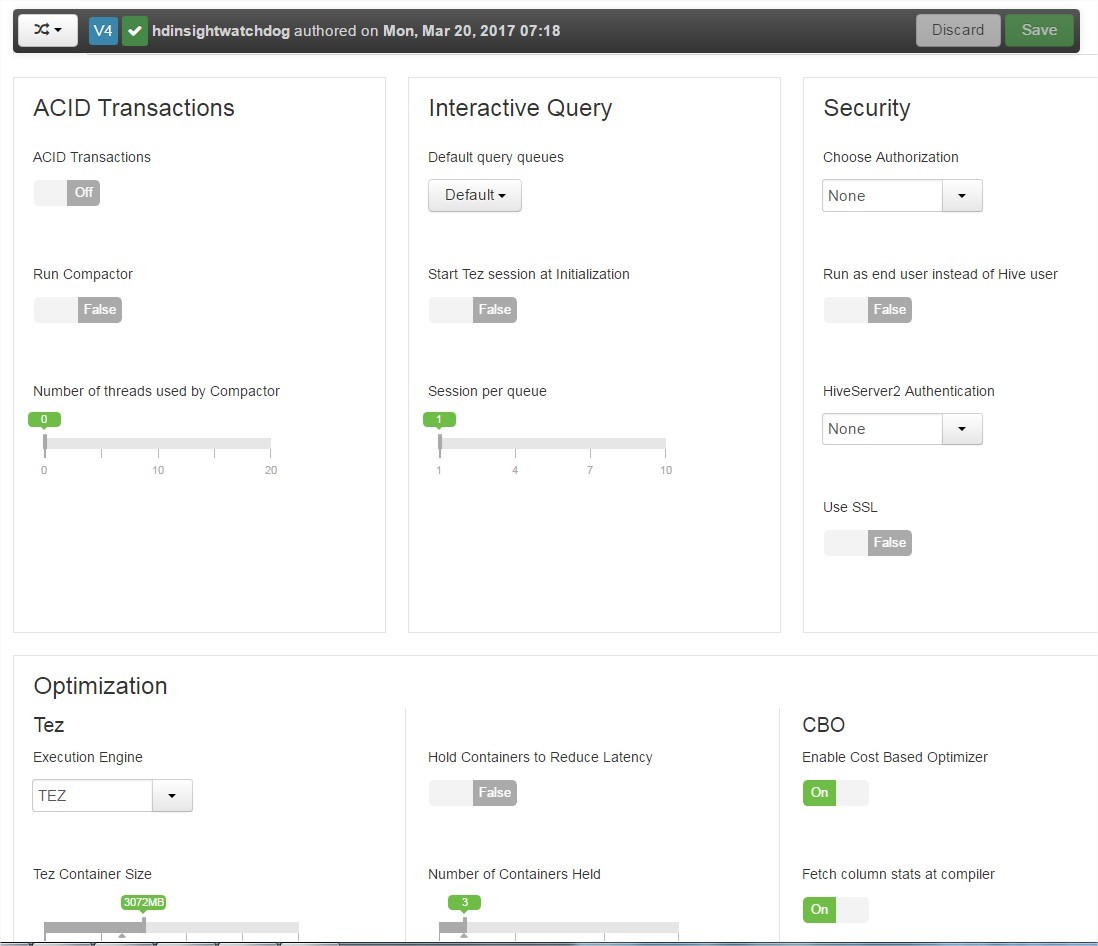
Interactive
- hive.execution.engine = tez;
- hive.server2.tez.initialize.default.sessions = true
- hive.server2.tez.default.queues = default
- hive.server2.tez.sessions.per.default.queue = max concurrent queries
- hive.prewarm.enabled = true
- hive.prewarm.numcontainers 1-5
- tez.am.session.min.held-containers 1-5
ETL
- hive.execution.engine = tez; (Rebuild index requriesmr)
- hive.server2.tez.initialize.default.sessions = false
- hive.server2.tez.default.queues = default
- hive.server2.tez.sessions.per.default.queue = 1
- hive.prewarm.enabled = false
- hive.prewarm.numcontainers = 0
- tez.am.session.min.held-containers = 0
JOIN STRATEGY
Shuffle (default)
- Slow, but works everytime Map (broadcast)
- Very fast, but limited
- One table has to fit in memory
- Understand Optimize Auto Join Conversion
- Default size for in-memory table is 10MB
- For star schemas consider loading dimension tables into memory
- In case of many joins, n-1 tables should fit in memory Bucket
- Very efficient, but difficult to setup
- Requries both tables to be bucketed and sorted on the same column
HIVE EXECUTION
(WebHCat vs HiveServer2)
- HiveServer2 starts queries faster
- WebHCar has more detailed history
- HiveServer2 is synchronous while WebHCat is asynchronous
- In Visual Studio HiveServer2 is called “Interactive”while WebHCat is called “Batch”
EXECUTION ENGINE OPTIMIZATION
| Type | Recommended | HDI Default |
| Joins | Bucket join/Sort Merge join | Shuffle |
| hive.auto.convert.join.noconditionaltask.size | 1/3 of -Xmx value | Auto-Tuned |
| tez.grouping.min-size | Decrease for better latency; Increase for more throughput | 16777216 |
| tez.grouping.max-size | Decrease for better latency; Increase for more throughput | 1073741824 |
| hive.exec.reducers.bytes.per.reducer | Decrease if reducers are the bottleneck | 256MB |
| hive.cbo.enable | true but need to rewrite tables | True |
| tez.am.resource.memory.mb | 4GB upper bound for most | Auto-Tuned |
| tez.session.am.dag.submit.timeout.secs | 300+ | 300 |
| tez.am.container.idle.release-timeout-min.millis | 20000+ | 10000 |
| tez.am.container.idle.release-timeout-max.millis | 40000+ | 20000 |
How to know what settings are used during TEZ query execution? Ambari/Tez view/«Query application ID»/ App Configuration/
More info: HDInsight performance Hive optimization Hive optimization #2 Hive join strategies Hive joins