
Šiandien išbandysime Google kalbos atpažinimo (speech to text) funkcionalumą. Google dar 2017 metai gyrėsi 95% anglų atpažinimo tikslumu, bet mane labiau domina JAV technologijų gigantės lietuvių kalbos gebėjimai.
Pirmieji bandymai užrašyti mano ištartas frazes paliko įspūdį, Google tik retkarčiais praleisdavo žodį ar įterpdavo nesąmonę. Pirmasis pastebėjimas - Google lietuvių kalbos atpažinimas yra labai jautrus kirčiavimui, pašaliniams garsams. Kilo mintis išbandyti šį funkcionalumą su profesionalaus lektoriaus garso įrašu: 2017 metų Nacionaliniu diktantu. Nusprendžiau parašyti programą, kurią būtų galima lengvai užleisti pakartotinai ir taip patikrinti funkcionalumo tobulėjimą ateityje.
Prisipažinsiu, bijau Google parašys diktantą geriau už mane :)
KTU tyrimas
2016 m. grupė KTU mokslininkų tyrė Google kalbos atpažinimo funkcionalumą. Atpažintų žodžių klaidų lygis (WER - Word Error Rate ) siekė 40%.
| 2016 m. problematiška frazė; | atpažinta kaip |
|---|---|
| penktas | tanki test |
| išsijunk | iš trijų |
| sviestas | speed test |
| lizosoma | visos stoma |
| taikyk | tai kiek |
| dešinėn | dešimt min |
| padidink | lady zippy |
| šunkelis | šunų kelis |
| išsijunk | iš jų |
| bjaurus | į eurus |
| rnr | prie neries |
| aštuntas | pašto kodas |
Pasiruošimas diktanto eksperimentui
- Surandu originalų tekstą ir audio įrašą Valstybinės lietuvių kalbos komisijos tinklapyje (VLKK)
Naktį pasnigo, miškas nubalo.
Nendrės, juosiančios ežerėlį, buvo tarytum paslaptingi
hieroglifai, kaligrafo įrėžti į tylą, neperskaitomi,
todėl nebylūs.
...
-
Formatuoju originalų tekstą sakinius perkeliant į atskiras eilutes (galimybė surasti audio failą pagal sakinio vietą faile)
-
Karpau audio failą į sakinius ir saugoju juos į atskirus failus
- Konfigūruoju Google Cloud: reikalingas Speech-To-Api planas ir Google Storage (nemokamas planas metams prisijungus pirmą kartą)
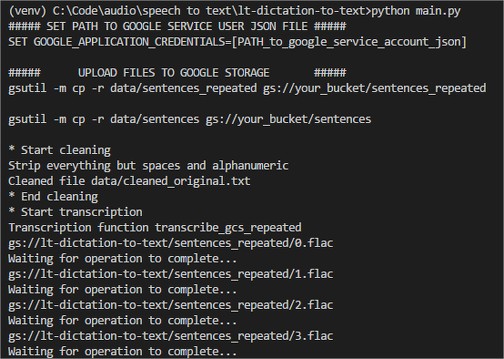
- Rašau Python programą: daugiau informacijos GitHub valdasm/lt-dictation-to-text
from google.cloud import speech
from google.cloud.speech import enums
from google.cloud.speech import types
client = speech.SpeechClient()
audio = types.RecognitionAudio(uri=gcs_uri)
config = types.RecognitionConfig(
encoding=enums.RecognitionConfig.AudioEncoding.FLAC,
sample_rate_hertz=44100,
language_code='lt-LT')
Diktanto rašymas
Pirmiausiai supraskime kokia yra audio įrašo struktūra: lektorius perskaito visą tekstą, tada lėtai skaito kiekvieną sakinį kartodamas frazes, galiausiai, lektorius dar kartą perskaito visą tekstą.
Sukurta Python programėlė siunčia tiek pilnų sakinių, tiek atskirų frazių pakartojimus. Pilnus sakinius lyginu su originaliu tekstu iš VLKK ir naudoju tolimesnei analizei.
Frazių atpažinimo rezultatai reikalauja mano įsikišimo norint sujungti viską į vientisus sakinius, tad eksperimentas nebebūtų objektyvus. Įdomumo dėlei, frazių atpažinimo tikslumo įverčius išsaugoju atskirame faile (data\raw_detailed_output.md).
Rezultatai
Atpažinimo įverčiai
Orginalas: Danius nedrąsiai šyptelėjo
Atmestas: Danijos migracija išėjo
Confidence: 0.72
Pasirinktas: Darius nedrąsiai šyptelėjo
Confidence: 0.73
Sakinių lyginimas
- danius nedrąsiai šyptelėjo
? ^
+ darius nedrąsiai šyptelėjo
? ^
- Orginalas
+ Google
Žodžių klaidų lygis
Google kalbos atpažinimo efektyvumui suskaičiuoti pasitelkiau žodžių klaidų lygio formule (kiek žodžių pašalinta, pakeista, nereikalingai įterpta iš visų žodžių originalo tekste).
Be kartojimo
Žodžių klaidų lygis (WER): 39.55% (Įterpta: 40 Pašalinta: 5 Pakeista: 95 Originalas: 354 )
Sakinio pakartojimas (naudojant skirtingus įrašus)
Žodžių klaidų lygis (WER): 36.44% (Įterpta: 19 Pašalinta: 14 Pakeista: 96 Originalas: 354 )
Įdomios frazės
“paslaptingi hieroglifai, kaligrafo įrėžti” -> “paslaptingi vyro klipai pririšti” “išgirdo švelnius vos juntamus” -> “švelnius losjonus”
Tobulinimas
1. Frazių kartojimas
Analizuojant atskirų frazių pasitikėjimo koeficjentus, matosi kad ištraukos yra kartais užrašomos tiksliau už sakinius. Tačiau jų logiškas sujungimas į vientisą sakinį jau reikalautų mano įsikišimo.
Orginalas: Rodėsi keista, kad neįmanoma pasakyti,
koks gi dabar paros metas
Pasirinktas: rūdys ir keista kad neįmanoma
pasakyti koks gi dabar paros metas
rūdys ir keista
0.8809462785720825
rodėsi keista
0.9402069449424744
Verčiant visą sakinį Google išgirdo “rūdys ir keista kad …”. Bet jau verčiant trumpas frazes, “rodėsi keista” buvo aptiktas su aukštu pasitikėjimo koeficjentu.
2. Nepasitikintis Google
Retkarčiais, Google pasirinko prastesnį vertimą (mano manymu):
Orginalas: Tėti, jeigu tas paveikslas tave gąsdina,
aš jį nukabinsiu
Pasirinktas: tai jeigu tas paveikslas Tele2
Confidence: 0.76
Atmestas: tiltai jeigu tas paveikslas tave gąsdina
aš nukrisiu
Confidence: 0.75
Antras sakinys yra arčiau tiesios, bet pasitikėjimo lygis yra didesnis prie pirmojo, kurį Google ir pasirinko.
3. Didžiųjų raidžių ir skyrybos ženklų nepaisymas
Google kalbos atpažinimas turi problemų su skyrybos ženklais. Kadangi norėjau pagrindinai atkreipti dėmesį tik į žodžių atpažinimą, originaliame tekste pašalinau skyrybos ženklus o didžiąsias raides paverčiau mažosiomis.
Apibendrinimas
Lietuvių kalba nėra taip populiari kaip anglų, tad ir teksto atpažinimas veikia ženkliai prasčiau. Be abejo, Google funkcionalumas tikrai tobulės, tad bus smagu pamatyti kaip atpažinimas veiks ateityje. KTU mokslininkų išsamus Google funkcionalumo testas atliktas 2016 metais vidutiniškai pasiekė 40% žodžių klaidų lygį. Mano mėgėjiškas eksperimentas su vieno lektoriaus įrašu - 36.44%.
Nuorodos: