
In this blog post, I am documenting two talks about privacy and design patterns that grabbed my attention.
Raghu Gollamudi in his talk “Privacy Ethics – A Big Data Problem” broadly covers best practices concerning Data Management aspects, applying Data Protection rules and “Privacy by design” methodologies to maintain good privacy hygiene.
Second speaker, Lars Albertsson in his talk “Privacy by design” discusses privacy, personal integrity and design patterns.
Data is exploding
- Data is being acquired/purchased at a rapid pace
- IOT data is ending up into massive data lakes (e.g., Strava exposing U.S. military bases)
- Application logs (e.g., collecting everything)
- Biased algorithms (e.g., offering new products to assumingly a pregnant girl)
Privacy vs. security
Privacy is:
- A fundamental right of the individual
- Focused on use of data based on bossiness and content
- Open to interpretation based on context and risk
- Under-invested market
Security is:
- A framework to protect information
- Focused on confidentiality and accessibility
- Clearly defined with explicit controls to monitor for and prevent authorized access
- Matured market
Privacy requirements from engineer’s perspective
- Right to be forgotten
- Limited collection
- Limited retention
- Limited access
- Consent for processing
- Right for explanations
- Right to correct data
- User data enumeration
- User data export
Solutions
Culture
- Customer/Employees first
- Performance reviews
Security
- Encrypt, Encrypt, Encrypt: Transit, Rest, Backups
- Robust Authentication mechanism
- Anonymization and/or Pseudoanonymization
- Store credentials in Vault storage
- Audit logs
Design
- Data integrity
- Authorization
- Obscurity by design
- Conservative approach to privacy settings by default
- Visibility and Transparency
- Privacy by Design The 7 Foundational Principles by Ann Cavoukian
Process
- Privacy related tasks part of scrum/sprint
- Data minimization
- Self service user management portal
- Honor user consent when processing user data
- Retention
Automation
- Discovery: Rest and in-motion (tagging, classifying, confidence scores; data sources, data formats, performance)
- Rules: Regulations, consent and contracts
- Issue management: Rule violations, issue resolution, subject access requests
Data classification
Personal information (PII) classification
- Red - sensitive data (messages, GPS location, preferences)
- Yellow - personal data (ID, name, email, address, IP address)
- Green - insensitive data (not related to persons)
- Grey zone - birth date, zip code, recommendation models
PI arithmetics
- red + green = red
- sum( red / yellow ) = green?
- yellow + yellow + yellow = red?
Make privacy visible at ground level
- In dataset names hdfs://red/crm/…
- In field names: user.y_name
Privacy protection patterns
Privacy protection at ingress
- Scramble on arrival
- Simple to implement
- Limits incoming data = limited value extraction
- Deanonymization possible
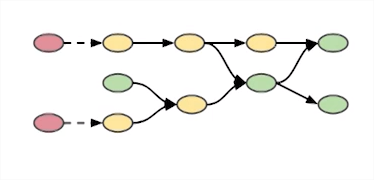 Privacy by design by Lars Albertsson
Privacy by design by Lars Albertsson
Privacy protection at egress
- Processing in opaque box
- Enabling
- Strict operations required
- Exploratory analytics need explicit egress/classification
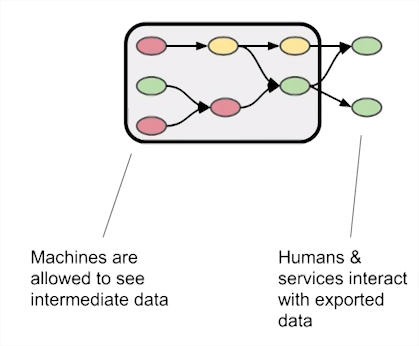 Privacy by design by Lars Albertsson
Privacy by design by Lars Albertsson
Right to be forgotten - data deletion
Anonymisation
- Discard all PII (e.g., User id)
- No link between records or datasets
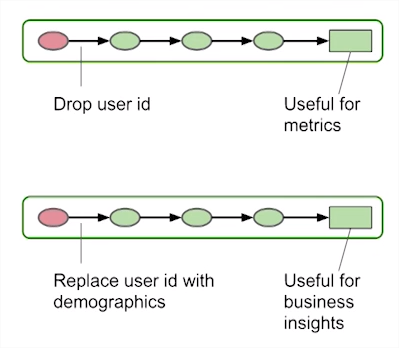 Privacy by design by Lars Albertsson
Privacy by design by Lars Albertsson
Pseudonymisation
- Records are linked
- Hash PII
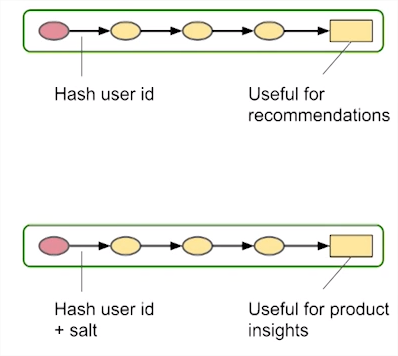 Privacy by design by Lars Albertsson
Privacy by design by Lars Albertsson
Re-computation
- Rerun all your datasets to remove customers
- Computationally expensive
- No versioning in tools
- No data model changes required
Ejected record pattern
- Mapping table, you keep PII in one table
- Ones user wants to be forgotten, delete one record
- It includes extra join in all selects
- PII table key needed (e.g., hash)
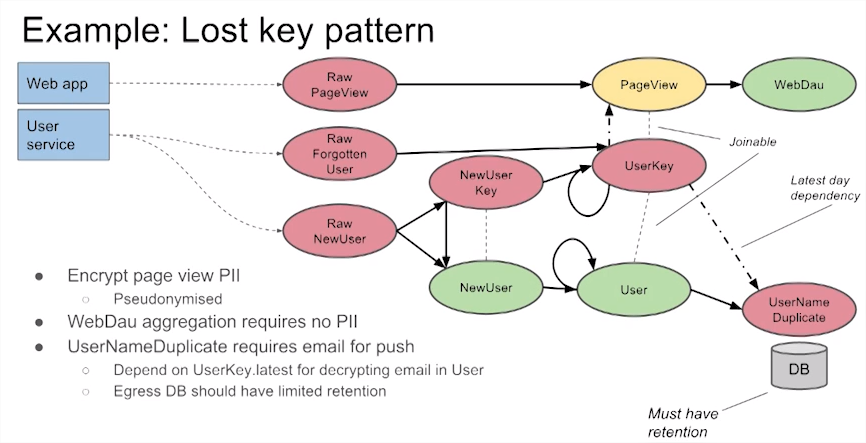
Lost key pattern
- PII fields encrypted
- Per-user decryption key table
- Extra join to decrypt
- Single dataset leak -> no PII leak
- Ones user wants to be forgotten, delete a key
- Instead of deleting a key, you can store a key in another place
 Privacy by design by Lars Albertsson
Privacy by design by Lars Albertsson
Data model deadly sins
- Using PII data as key (username, email)
- Publishing entity ids containing PII data (e.g. user shared resources including username
- Publishing pseudonymized datasets (can be de-pseudonymized with external data)