
Prieš savaitę dalinausi savo įžvalgomis apie dirbtinį intelektą ir Azure duomenų analitikos paslaugas Microsoft Lietuva organizuotoje konferencijoje. Kadangi daugiausiai klausimų sulaukiau apie „duomenų ežerą“ (angl. Data Lake), nusprendžiau surašyti savo mintis apie pagrindinius bruožus ir atsakyti į dažniausiai girdimus klausimus apie šias duomenų talpyklas.
 Photo by Joshua Ness on Unsplash
Photo by Joshua Ness on Unsplash
Palyginkime duomenų saugyklą su „duomenų ežeru“
Išsklaidykime mitus apie „duomenų ežerą“
“If you think of a data mart as a store of bottled water - cleansed and packaged and structured for easy consumption - the data lake is a large body of water in a more natural state” - James Dixon, Pentaho CTO
„Duomenų ežeras“ dažnai yra siejamas su dideliais duomenimis (angl. Big Data) ir pristatomas kaip bedugnė duomenų talpykla. Tačiau tai tik „duomenų ežero“ galimybių ledkalnio viršūnė.
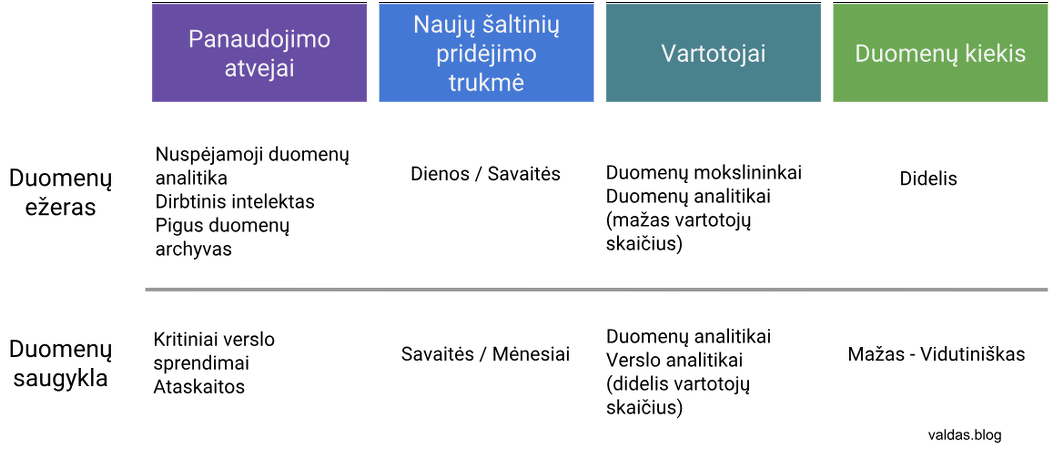
Vis didėjantys duomenų analitikos poreikiai ir atsirandančios dirbtinio intelekto idėjos reikalauja lanksčių sprendimų duomenų paruošimui, net jei ir įmonė neturi didžiulių duomenų kiekių. Duomenų specialistai gali rinktis duomenų saugyklą (angl. Data Warehouse), „duomenų ežerą“, arba abu variantus.
Duomenų saugykla
Duomenų saugyklose saugoma apibendrinta informacija apie tam tikrus įmonės veiklos aspektus, pvz.: klientus, produktus, pardavimus. Vėliau, šie duomenys gali būti atvaizduojami ataskaitose ar naudojami verslo sistemose. Kuriant duomenų saugyklą, įrašai išgaunami ir integruojami iš įvairių duomenų šaltinių, pvz.: CRM, taikomųjų programų.
Egzistuoja du pagrindiniai duomenų saugojimo būdai: normalizuota (grupuojam pagal normalizacijos formas) ir dimensinė struktūra (skaidom į faktus ir dimensijas). Sukūrus duomenų saugyklą, galutiniams vartotojams sukuriami departamento lygiai (angl. data marts), kur saugomi tik išvestiniai duomenys, sukurti pagal atitinkamų skyrių poreikius.
Palyginkime duomenų saugyklą su „duomenų ežeru“
Kada naudinga turėti duomenų ežerą, o kada duomenų saugyklą? Visų pirma, abi platformos sprendžia skirtingas problemas ir yra diegiamos skirtingiems naudojimo atvejams.
Svarstant „duomenų ežero“ diegimą, pravartu atsakyti į šiuos klausimus:
- Ar turite ne reliacinių duomenų šaltinių (pvz., NoSQL, grafinės duomenų bazės)?
- Ar turite realaus laiko ir didelius duomenų kiekius (pvz., IoT įrenginiai)?
- Ar turite dirbtinio intelekto scenarijus ant nestandartinių duomenų (pvz., nuotraukos, dokumentai)?
- Ar ieškote pigesnės alternatyvos istorinių duomenų saugojimui?
Išsklaidykime mitus apie „duomenų ežerą“
Mitas #1 - „Duomenų ežeras“ saugo duomenis nestruktūriškai, be duomenų hierarchijos ar organizavimo
Tiesa, jame saugomi duomenys yra neapdoroti, priima ir išlaiko duomenis iš visų duomenų šaltinių, palaiko visus duomenų tipus ir schemas. Tačiau duomenų saugojimo vieta ir kitos taisyklės yra apibrėžiamos pagal atitinkamus duomenų apdorojimo ir naudojimo reikalavimus.
Mitas #2 - Duomenis pasiekti ir analizuoti gali visi įmonės darbuotojai
Prieigos gali būti duodamos atsižvelgiant į teisinius (ką darbuotojas gali matyti) ir sudėtingumo aspektus (didžioji dalis vartotojų norės matyti tik sutvarkytus ir išvestinius duomenis).
Mitas #3 - „Duomenų ežero“ įgyvendinimui reikalinga Hadoop platforma
Hadoop, o tiksliau HDFS (Hadoop Distributed File System), tai paskirstytų failų sistema. Tiesa, „duomenų ežero“ konceptas įsitvirtino būtent kaip gairių rinkinys duomenų analitikai Hadoop platformoje, diegiant Cloudera ar Hortonworks sprendimus. Tada, debesijos paslaugų tiekėjai pradėjo tobulinti savo duomenų saugojimo paslaugas ir sukūrė pigias bei labai galingas alternatyvas. Microsoft Azure turi Azure Data Lake Store Gen 2, Amazon Web Services didžiuojasi S3 saugykla, o Google Cloud Platform turi Google Big Query.
Nebereikia užsakinėti brangių serverių ar licencijų - paslaugos sukuriamos kelių mygtukų paspaudimu ir lygiai taip pat lengvai panaikinamos kai resursų nebenaudojate.
„Duomenų ežero“ bruožai
„Duomenų ežerą“ sudaro bent 4 sluoksniai: neapdoroti duomenys, transformuoti duomenys, taikomųjų programų duomenys, tyrinėjimo zona ir metaduomenys. Priklausomai nuo duomenų sudėtingumo, organizacijos dydžio ar panaudojimo scenarijų, atsiranda daugiau sluoksnių. Aptarkime pačius pagrindinius elementus ir jų bruožus:
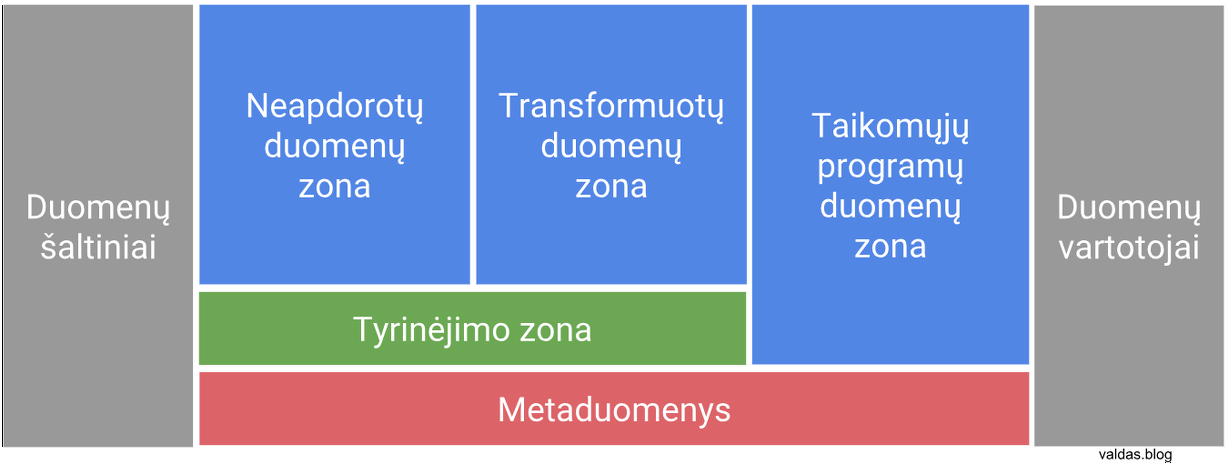
Neapdorotų duomenų zona (angl. raw zone)
Į šią erdvę sudedami duomenys nėra apdorojami ir išlaiko visą informaciją. Naujų duomenų šaltinių įkėlimas į automatizuotą duomenų ežerą įprastai trunka kelias dienas, skirtingai nei duomenų saugyklos integravimo darbai, kurie gali tęstis savaites ar mėnesius. Neapdorotų duomenų zonoje duomenys nekinta, tai reiškia, kad nauji duomenys įrašomi, juos pridedant prie jau esamų duomenų, o ne juos pakeičiant. Yra išimčių, pvz.: įsipareigojimai pašalinti duomenis kliento prašymu. Prieigą prie šios zonos įprastai turi tik duomenų ekspertai išmanantys duomenų šaltinių niuansus.
Importuojamų duomenų formatai dažnai skirtingi: galime aptikti tiek ir populiarius failus kaip Excel/CSV, sudėtingesnius kaip JSON/XML, o net ir nuotraukas ar garso įrašus (pvz., skambučių centro pokalbių įrašai sentimentų analizei). „Duomenų ežeras“ ne tik saugo įvairius duomenis, bet ir teikia įrankius tokių duomenų apdorojimui (pvz., Apache Spark).
Transformuotų duomenų zona (angl. curated zone)
Didžioji dalis vartotojų nori matyti sutvarkytus ir išvestinius duomenis, neišrandant dviračio kiekvienos naujos ataskaitos kūrimo metu. Įprastai, duomenų integruotojai “įkelia” duomenis į neapdorotų duomenų zoną, agreguoja ir išsaugo rezultatus transformuotų duomenų zonoje.
Transformuotų duomenų zona dažnai yra skirstoma į šias dalis:
- Pagrindai (master) - klientai, produktai, dokumentai, tiekėjai
- Transakcijos (transactional) - pardavimai, apmokėjimai
- Nuorodos (reference) - produktų hierarchija, šalys, pagalbiniai kodai
- Duomenų produktai - duomenų analitikų ir duomenų mokslininkų sukurti išvestiniai duomenų rinkiniai ir dirbtinio intelekto modeliai
Tyrinėjimo zona (angl. sandbox)
Duomenų mokslininkai (angl. Data Scientists) yra atsakingi už šiuolaikinių analizės ir prognozavimo metodų taikymą. Jie puikiai supranta verslo procesus, duomenų loginį modelį ir geba sudaryti matematinius modelius bei algoritmus pagrįstiems verslo sprendimams priimti.
Tyrinėjimo zona tai prielaidų tikrinimo aplinka palaikanti įvairius įrankius ir įvairaus galingumo resursus, priklausomai nuo užduoties ir vartotojų įgūdžių. Debesijos sprendimai leidžia kurti resursus pagal reikalavimą (angl. on-demand), pvz.: jei prielaidos patvirtinimui ar paneigimui reikalingas galingesnis serveris, tokius resursus galima per kelias minutes užsakyti ir mokėti tik už naudojimo laiką.
Negalima integruoti verslo kritinių sistemų su trumpalaikiais tyrinėjimo zonos duomenimis, o sukurti matematiniai modeliai bei algoritmai privalo būti automatizuoti. Čia atsiranda duomenų inžinieriai, kurie glaudžiai dirba su duomenų mokslininkais ruošiant duomenis, tobulinant programinį kodą ir diegiant sprendimus į darbinę vartotojų aplinką.
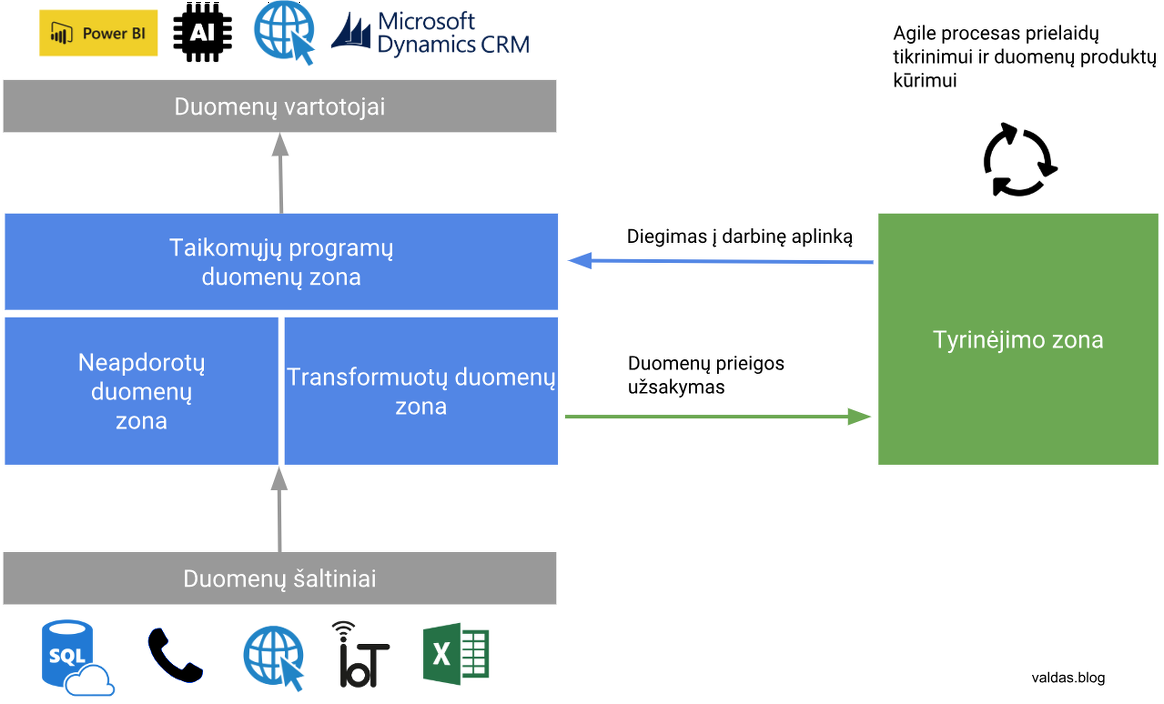
Taikomųjų programų duomenys (angl. application data layer)
Į šią erdvę sudedami išvestiniai duomenys, sukurti pagal atitinkamus skyrių poreikius, pvz.:
- Duomenų prieiga per API sąsajas
- PowerBI, Tableau ar SAS integracijos
- Realaus laiko sprendimai paremti dirbtiniu intelektu
Metaduomenys
Kiekvienas „duomenų ežeras“ privalo įgyvendinti metaduomenų saugyklą, kaupiančią atsakymus į šiuos klausimus:
- Kokius duomenis vartotojai gali surasti „duomenų ežere“?
- Koks duomenų formatas, schema, kaip skaityti?
- Kaip duomenys yra integruoti tarpusavyje (angl. lineage)?
- Kas ir prie ko turi prieigą, kas yra atsakingas už duomenų šaltinius ir integraciją?
- Kaip duomenys yra apdorojami (konvertuojami, formatuojami, išdėstomi nuosekliai, apibendrinami ir t. t.)?
- Kokiems tikslas yra naudojami duomenų produktai (pvz., dirbtinio intelekto modeliai)?
Tvarkingai susistemintus metaduomenis galima atvaizduoti duomenų valdymo programose, pvz.: Collibra, Datum, IBM Governance Catalog, Informatica Information Catalog.
Duomenų saugojimo ir prieigos ypatumai
Duomenys „duomenų ežere“ yra saugojami kaip failai, tačiau vartotojai prie duomenų gali prieiti skirtingais būdais. Apache Hive ar Apache Spark įrankiai leidžia naudoti SQL sąsają duomenų operacijoms atlikti ir slepia nuo vartotojo failų išsaugojimo vietą ar formatą. Atitinkamai pavadinti duomenų aplankai gali elgtis kaip skaidiniai (angl. partition): skaitomas tik sąlygoje nurodytas aplankas.

„Duomenų ežeras“ tai lanksti duomenų saugojimo ir apdorojimo sistema, skirta duomenų analitikos ir dirbtinio intelekto panaudos atvejams įgyvendinti. Debesijos sprendimų dėka vartotojai gali išbandyti įvairius įrankius be didžiulių investicijų: paslaugos yra lengvai plečiamos didėjant poreikiams, o kaina nustatoma pagal resursų panaudojimą.
Pradžiai, siūlau išbandyti Azure Databricks ir Azure Data Lake Gen 2 pagal šį pavyzdį.