
Gartner’s Hype Cycle for Data Management 2018 included DataOps as an emerging topic. Various data analytics vendors picked up the newly-formed term and started offering prepackaged “DataOps solutions”. That triggered a response from Gartner:
DataOps is a practice, not a technology or tool; you cannot buy it in an application. It’s a cultural change supported by tooling, and many of your existing tools may be adequate to bring in the required levels of automation demanded by DataOps. - Hyping DataOps by Nick Heudecker, Gartner
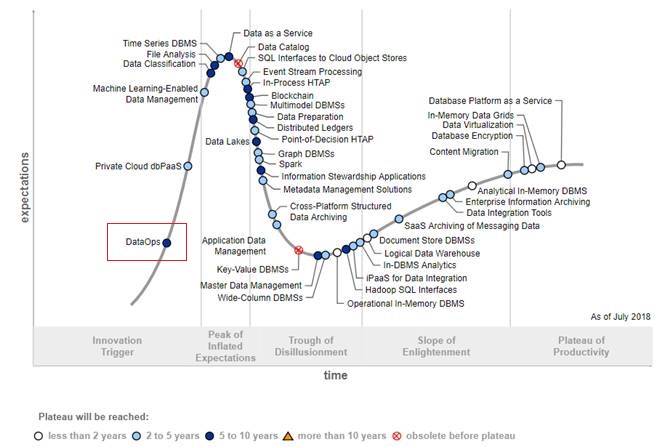 Gartner Hype Cycle for Data Management, 2018
Gartner Hype Cycle for Data Management, 2018
As Nick Heudecker pointed out in “Hyping DataOps” article, DataOps should focus more on reducing the experience and skills mismatch between technical and non-technical staff. But before we focus on reducing the gap, it is important to understand the data technology landscape.
A rising number of companies undertaking data analytics projects eventually faced the complexity of growing data pipelines. Employing automated deployment and testing for data projects has always been tricky: data pipelines becoming data silos, no collaboration or reuse, constant data quality issues, and slow delivery times.
The world of software engineering was plagued with similar issues until it introduced agile development and DevOps techniques. Today, DevOps pioneers, such as Google, Amazon, and Facebook, deploy software releases hourly, if not faster—a development cycle unimaginable a few years ago. Even though deployment cycle times have accelerated, software defects have declined. The introduction of microservices and containerization further accelerates and hardens delivery cycles. It’s safe to state that DevOps delivers better code, faster, at less cost.
The data world is implementing DevOps principles with a twist. Whereas DevOps manages the cooperation of code, tools, and infrastructure to speed up the delivery of applications, DataOps adds the fourth element - data. To be more precise, data must be identified, captured, formatted, tagged, validated, cleaned, transformed, aggregated, secured, governed, visualized, analyzed, and acted upon. Everything gets even more complex as organizations have ambitions to use machine learning, utilize previously unexplored datasets, focus on building data-driven solutions.
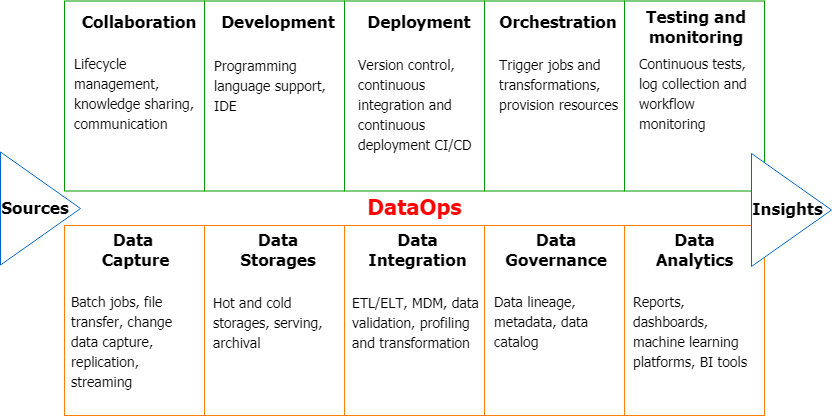
“Diving into DataOps: The Underbelly of Modern Data Pipelines” article splits DataOps into multiple process and technologies. The below diagram is my version, inspired by Eckerson’s blog post.
DataOps - high-level view
DataOps - example tools
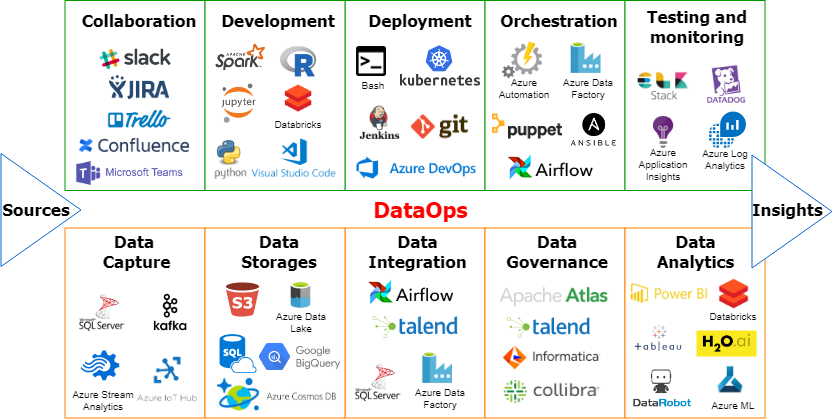
Splitting the tools into the above 10 categories showcases the variety of problems data people need to solve to get valuable insights. It seems that there are many adequate tools to bring in the required levels of automation. However, as Google VP Bill Coughran once said:
“Engineering is easy, people are hard.”
The right tools are just a part of the DataOps equation. Next step is a cultural change to reduce the gap between technical and non-technical staff. According to Gartner, it will take the next 5-10 years for DataOps frameworks and standards to emerge.
Links
- Hyping DataOps
- DataOps Explained: A Remedy For Ailing Data Pipelines
- Diving into DataOps: The Underbelly of Modern Data Pipelines
- The Best DataOps Articles of Q3 2018
When #dataanalytics meets #devops